As part of an upcoming workshop, I've been rebuilding a spreadsheet developed by someone else to use as a communication tool. The good news is that I was handed most of the necessary formulas. The bad news was that I needed to completely start from scratch with the design, and I still had a lot to learn along the way. This spreadsheet was like Steve Austin, even if it wasn't a $6M spreadsheet.
Here was my to do list:
- How do you get Excel to display ordinal numbers?
- Can you make something that looks like a number line...and add dynamic data to it?
- How do you display a normal curve...and add dynamic data to it?
Fortunately, between Google, YouTube, and Twitter, I was able to make short work of this list. Here is how everything is coming together. This is very much a work in progress---so if you have ideas to help make this awesome, I'd love to hear them.
The goal here is to allow a user to input a value for
Effect Size and see how that relates to a variety of other measures: an
Improvement Index, the
standard deviation, and
variance.
Below the space for input, I have set up the space for the other measures.
Before we talk nuts and bolts, I want to talk a little about design here. This is a tool that will be handed off for others to use---and has to enable them to communicate with their own stakeholders. Whatever gets placed in the workbook has to be both rich in meaning and self-explanatory. I want a very simple layout and colour scheme to help direct the eye. I also want to be sure that even if someone is not comfortable with statistics that they could still gain some insight from the graphics. The baseline information in the sheet remains grey; values turn green. This is what a user would see if the effect size is .4:
So far, I like it. I'm wondering about adding some conditional formatting to indicate the strength of an effect. In other words, is an r value of .2 "good"? It may be too much to put here, but it would be great to have a way to help people compare or evaluate what they see. For example, in the education world,
an effect size of .4 is the average. Anything below that still represents something effective, but if you're looking to make a big impact in the classroom, perhaps that particular strategy might not be the best. Is this important to add? What about other explanations/resources?
Okay, so let's take a bionic jump into the nuts and bolts and the questions I had above. The first one, about ordinal numbers, came from developing the text shown on the right. The sentence you see is based on a formula: some text in quotes, the "&" symbol, and cells with the dynamic values (in this example, 66% and 66th). But Excel has no function for displaying ordinal versions of numbers. So, how do you tell Excel when to use
st, nd, rd, or
th at the end of a number?
According to Teh Googles, you use this formula
=A1&MID("thstndrdth",MIN(9,2*RIGHT(A1)*(MOD(A1-11,100)>2)+1),2), where "A1" equals the cell with the number you want to add the ordinal ranking to. I grabbed the
formula from here, and the post also includes an awesome explanation of why it works. In my spreadsheet, I used three cells for this. The first was for the actual calculation using the NORM.DIST function (=NORM.DIST(EffectSize,0,1,TRUE). Even though I can choose to display the results of that cell using two digits, Excel is sneaky and remembers the whole string. So, as an intermediate step, I had Excel take the contents of the cell and change it into text =TEXT((D2*100),"0"). Now it can't use a long trailing decimal. Take that! I used the contents of this cell for the ordinal formula.
A magic button to insert a normal distribution is missing, too. Are we or are we not living in the 21st century? No flying cars. No "normal" chart in Excel. WTH? My kludge, in this case, was taken from a
YouTube video and workbook that I grabbed information from ExcelIsFun. I copied values from the workbook and created a basic area graph. For the dynamic green region, I used the following formula =IF(H3<=Variance,I3,""), where "H3" was the cell with the value for the x-axis of the graph (I had to make all values positive) and I3 had the value I copied from the workbook---the one matching the grey graph. This creates a very narrow range of data points around 0 standard deviations, which are then added to the graph.
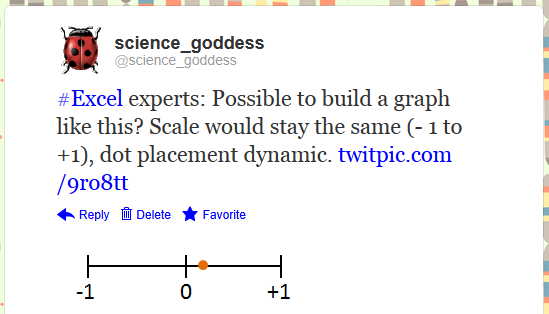
The answer for the final piece, the line-type graph for variance, came from a Twitter shout-out.
I drew what I wanted, attached it to the tweet, and crossed my fingers for brilliant ideas to head my way. Here are the two I received:
I ended up deciding to just have the scale go from 0 to +1. There are negative correlations, but with the formula I was using from the original spreadsheet, there was no possibility of ending up with a negative result.
This has been a great small project to work on. It's also been a reminder that you don't have to know everything about Excel to get where you want to go. There's lots of help available from those who have previously solved problems. Makes it easy to rebuild, reuse, recycle the worksheets you have.
We can rebuild our workbooks. We have the technology. We have the
capability to make the world's best spreadsheet. Our workbook will
have that spreadsheet. Better than it was before. Better...stronger...faster...
Bonus Round
If you want to play around with the workbook, you can
download it here. The final version will be made available at a workshop in two weeks, so if you have any feedback or improvements to suggest, get on it.
Sounds from the Bionic Woman and Six Million Dollar Man from
here.